Time Series Classification
Time Series Classification with SKTime
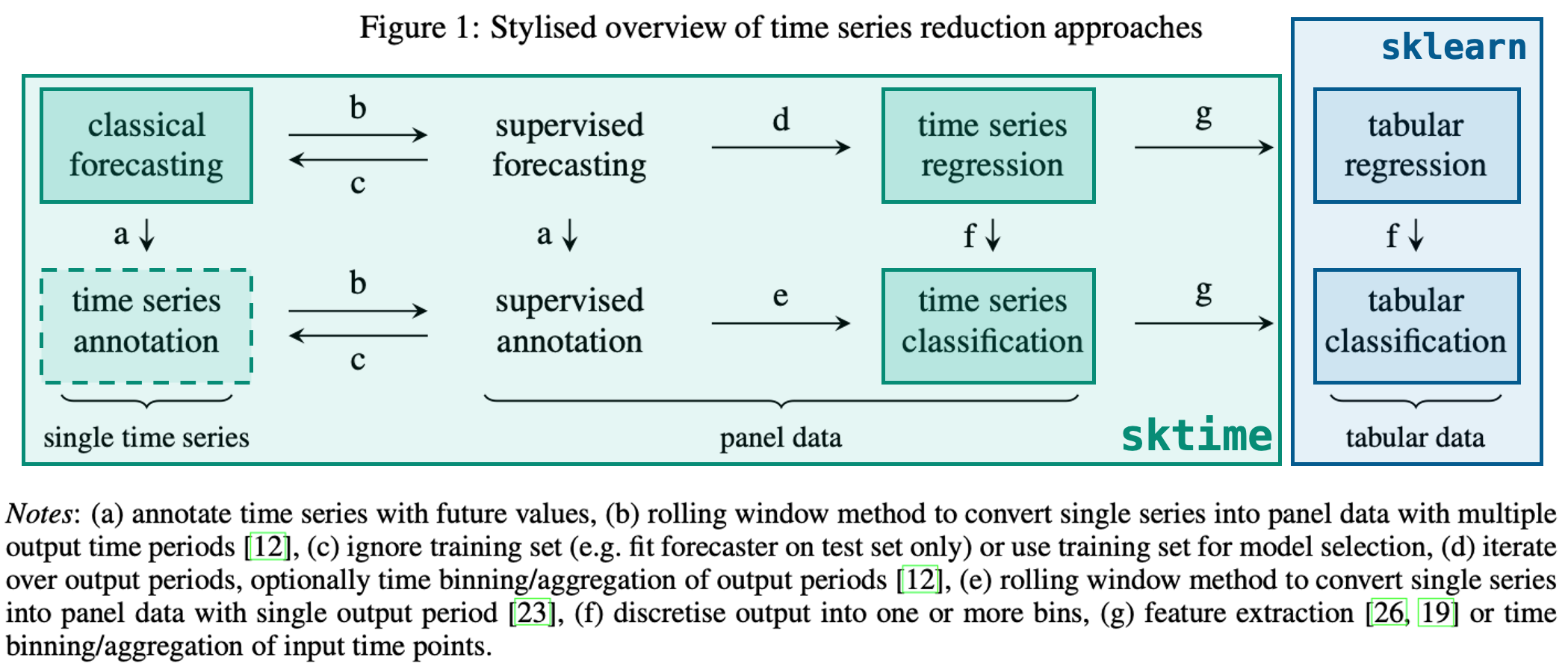
Resources
!pip install sktimeCollecting sktime
Downloading sktime-0.13.4-py3-none-any.whl (7.0 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.0/7.0 MB 36.0 MB/s eta 0:00:00
Requirement already satisfied: pandas<1.6.0,>=1.1.0 in /opt/conda/lib/python3.7/site-packages (from sktime) (1.3.5)
Requirement already satisfied: numpy<1.23,>=1.21.0 in /opt/conda/lib/python3.7/site-packages (from sktime) (1.21.6)
Requirement already satisfied: scikit-learn<1.2.0,>=0.24.0 in /opt/conda/lib/python3.7/site-packages (from sktime) (1.0.2)
Requirement already satisfied: statsmodels>=0.12.1 in /opt/conda/lib/python3.7/site-packages (from sktime) (0.13.2)
Collecting deprecated>=1.2.13
Downloading Deprecated-1.2.13-py2.py3-none-any.whl (9.6 kB)
Requirement already satisfied: scipy<1.9.0 in /opt/conda/lib/python3.7/site-packages (from sktime) (1.7.3)
Requirement already satisfied: numba>=0.53 in /opt/conda/lib/python3.7/site-packages (from sktime) (0.55.2)
Requirement already satisfied: wrapt<2,>=1.10 in /opt/conda/lib/python3.7/site-packages (from deprecated>=1.2.13->sktime) (1.12.1)
Requirement already satisfied: llvmlite<0.39,>=0.38.0rc1 in /opt/conda/lib/python3.7/site-packages (from numba>=0.53->sktime) (0.38.1)
Requirement already satisfied: setuptools in /opt/conda/lib/python3.7/site-packages (from numba>=0.53->sktime) (59.8.0)
Requirement already satisfied: python-dateutil>=2.7.3 in /opt/conda/lib/python3.7/site-packages (from pandas<1.6.0,>=1.1.0->sktime) (2.8.2)
Requirement already satisfied: pytz>=2017.3 in /opt/conda/lib/python3.7/site-packages (from pandas<1.6.0,>=1.1.0->sktime) (2022.1)
Requirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/lib/python3.7/site-packages (from scikit-learn<1.2.0,>=0.24.0->sktime) (3.1.0)
Requirement already satisfied: joblib>=0.11 in /opt/conda/lib/python3.7/site-packages (from scikit-learn<1.2.0,>=0.24.0->sktime) (1.0.1)
Requirement already satisfied: patsy>=0.5.2 in /opt/conda/lib/python3.7/site-packages (from statsmodels>=0.12.1->sktime) (0.5.2)
Requirement already satisfied: packaging>=21.3 in /opt/conda/lib/python3.7/site-packages (from statsmodels>=0.12.1->sktime) (21.3)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /opt/conda/lib/python3.7/site-packages (from packaging>=21.3->statsmodels>=0.12.1->sktime) (3.0.9)
Requirement already satisfied: six in /opt/conda/lib/python3.7/site-packages (from patsy>=0.5.2->statsmodels>=0.12.1->sktime) (1.15.0)
Installing collected packages: deprecated, sktime
Successfully installed deprecated-1.2.13 sktime-0.13.4
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
Methodology
Using sktime for classification is similar to using it for forecasting wherein there are either predefined models or we can transform exising sklearn models to make them usable with time series data
Importing Data
We can import the arrow head dataset and graph some of the entries
import pandas as pd
from sktime.datasets import load_arrow_head
from sktime.utils.plotting import plot_series
from sklearn.model_selection import train_test_split
X, y = load_arrow_head()X.head()| dim_0 | |
|---|---|
| 0 | 0 -1.963009 1 -1.957825 2 -1.95614... |
| 1 | 0 -1.774571 1 -1.774036 2 -1.77658... |
| 2 | 0 -1.866021 1 -1.841991 2 -1.83502... |
| 3 | 0 -2.073758 1 -2.073301 2 -2.04460... |
| 4 | 0 -1.746255 1 -1.741263 2 -1.72274... |
y[:5]array(['0', '1', '2', '0', '1'], dtype='<U1')
X_0 = list(X['dim_0'][0])
plot_series(pd.Series(X_0))(<Figure size 1152x288 with 1 Axes>, <AxesSubplot:>)

X_1 = list(X['dim_0'][1])
plot_series(pd.Series(X_1))(<Figure size 1152x288 with 1 Axes>, <AxesSubplot:>)

Train/Test Split
Train/Test splitting can be cone using sklearn as normal since each row is a different series/observation
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y)Using a Classifier
sktime has built in classifiers that can be used as normal sklearn classifiers:
from sktime.classification.interval_based import TimeSeriesForestClassifierclassifier = TimeSeriesForestClassifier()
classifier.fit(X_train, y_train)TimeSeriesForestClassifier()
And predictions can be made using the predict method:
y_pred = classifier.predict(X_test)Model Evaluation
We can also check the accuracy using normal sklearn metrics, for example accuracy_score
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred)0.9056603773584906
from sklearn.metrics import confusion_matrix
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
matrix = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(matrix)
disp.plot()<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7f826205ddd0>

Use with SKLearn Classifiers
sktime also allows the conversion of data such that it can be used with sklearn tabular classifiers. This is done by transforming the classifier using the Tabularizer in a sklearn pipeline
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.pipeline import make_pipeline
from sktime.transformations.panel.reduce import Tabularizerclassifier = make_pipeline(Tabularizer(), GradientBoostingClassifier())
classifier.fit(X_train, y_train)Pipeline(steps=[('tabularizer', Tabularizer()),
('gradientboostingclassifier', GradientBoostingClassifier())])y_pred = classifier.predict(X_test)accuracy_score(y_test, y_pred)0.9056603773584906
matrix = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(matrix)
disp.plot()<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7f8261ebb810>
