Time Series Forecasting
Forecasting with SKTime
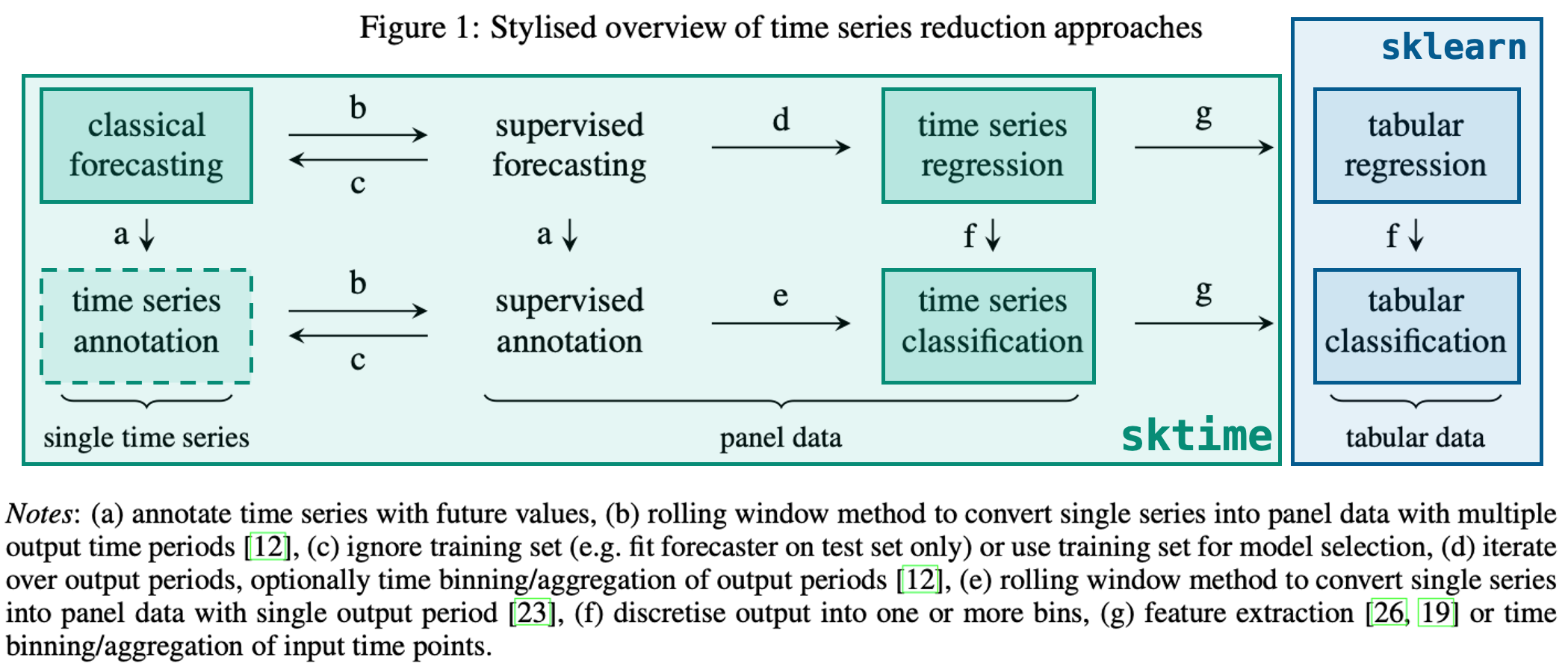
Resources
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session/kaggle/input/nab/README.md /kaggle/input/nab/realKnownCause/realKnownCause/rogue_agent_key_updown.csv /kaggle/input/nab/realKnownCause/realKnownCause/ec2_request_latency_system_failure.csv /kaggle/input/nab/realKnownCause/realKnownCause/ambient_temperature_system_failure.csv /kaggle/input/nab/realKnownCause/realKnownCause/nyc_taxi.csv /kaggle/input/nab/realKnownCause/realKnownCause/rogue_agent_key_hold.csv /kaggle/input/nab/realKnownCause/realKnownCause/machine_temperature_system_failure.csv /kaggle/input/nab/realKnownCause/realKnownCause/cpu_utilization_asg_misconfiguration.csv /kaggle/input/nab/realTraffic/realTraffic/TravelTime_387.csv /kaggle/input/nab/realTraffic/realTraffic/speed_6005.csv /kaggle/input/nab/realTraffic/realTraffic/speed_t4013.csv /kaggle/input/nab/realTraffic/realTraffic/occupancy_t4013.csv /kaggle/input/nab/realTraffic/realTraffic/speed_7578.csv /kaggle/input/nab/realTraffic/realTraffic/occupancy_6005.csv /kaggle/input/nab/realTraffic/realTraffic/TravelTime_451.csv /kaggle/input/nab/realTraffic/realTraffic/.DS_Store /kaggle/input/nab/realTraffic/__MACOSX/realTraffic/._speed_6005.csv /kaggle/input/nab/realTraffic/__MACOSX/realTraffic/._occupancy_6005.csv /kaggle/input/nab/realTraffic/__MACOSX/realTraffic/._.DS_Store /kaggle/input/nab/artificialNoAnomaly/artificialNoAnomaly/art_daily_no_noise.csv /kaggle/input/nab/artificialNoAnomaly/artificialNoAnomaly/art_noisy.csv /kaggle/input/nab/artificialNoAnomaly/artificialNoAnomaly/art_daily_small_noise.csv /kaggle/input/nab/artificialNoAnomaly/artificialNoAnomaly/art_flatline.csv /kaggle/input/nab/artificialNoAnomaly/artificialNoAnomaly/art_daily_perfect_square_wave.csv /kaggle/input/nab/artificialWithAnomaly/artificialWithAnomaly/art_daily_flatmiddle.csv /kaggle/input/nab/artificialWithAnomaly/artificialWithAnomaly/art_increase_spike_density.csv /kaggle/input/nab/artificialWithAnomaly/artificialWithAnomaly/art_daily_jumpsup.csv /kaggle/input/nab/artificialWithAnomaly/artificialWithAnomaly/art_daily_nojump.csv /kaggle/input/nab/artificialWithAnomaly/artificialWithAnomaly/art_load_balancer_spikes.csv /kaggle/input/nab/artificialWithAnomaly/artificialWithAnomaly/art_daily_jumpsdown.csv /kaggle/input/nab/realAWSCloudwatch/realAWSCloudwatch/elb_request_count_8c0756.csv /kaggle/input/nab/realAWSCloudwatch/realAWSCloudwatch/ec2_cpu_utilization_53ea38.csv /kaggle/input/nab/realAWSCloudwatch/realAWSCloudwatch/iio_us-east-1_i-a2eb1cd9_NetworkIn.csv /kaggle/input/nab/realAWSCloudwatch/realAWSCloudwatch/ec2_cpu_utilization_5f5533.csv /kaggle/input/nab/realAWSCloudwatch/realAWSCloudwatch/ec2_cpu_utilization_ac20cd.csv /kaggle/input/nab/realAWSCloudwatch/realAWSCloudwatch/ec2_cpu_utilization_24ae8d.csv /kaggle/input/nab/realAWSCloudwatch/realAWSCloudwatch/ec2_disk_write_bytes_c0d644.csv /kaggle/input/nab/realAWSCloudwatch/realAWSCloudwatch/ec2_network_in_257a54.csv /kaggle/input/nab/realAWSCloudwatch/realAWSCloudwatch/ec2_cpu_utilization_fe7f93.csv /kaggle/input/nab/realAWSCloudwatch/realAWSCloudwatch/ec2_cpu_utilization_c6585a.csv /kaggle/input/nab/realAWSCloudwatch/realAWSCloudwatch/ec2_disk_write_bytes_1ef3de.csv /kaggle/input/nab/realAWSCloudwatch/realAWSCloudwatch/ec2_cpu_utilization_77c1ca.csv /kaggle/input/nab/realAWSCloudwatch/realAWSCloudwatch/grok_asg_anomaly.csv /kaggle/input/nab/realAWSCloudwatch/realAWSCloudwatch/ec2_network_in_5abac7.csv /kaggle/input/nab/realAWSCloudwatch/realAWSCloudwatch/rds_cpu_utilization_e47b3b.csv /kaggle/input/nab/realAWSCloudwatch/realAWSCloudwatch/rds_cpu_utilization_cc0c53.csv /kaggle/input/nab/realAWSCloudwatch/realAWSCloudwatch/ec2_cpu_utilization_825cc2.csv /kaggle/input/nab/realTweets/realTweets/Twitter_volume_UPS.csv /kaggle/input/nab/realTweets/realTweets/Twitter_volume_CVS.csv /kaggle/input/nab/realTweets/realTweets/Twitter_volume_PFE.csv /kaggle/input/nab/realTweets/realTweets/Twitter_volume_CRM.csv /kaggle/input/nab/realTweets/realTweets/Twitter_volume_AMZN.csv /kaggle/input/nab/realTweets/realTweets/Twitter_volume_KO.csv /kaggle/input/nab/realTweets/realTweets/Twitter_volume_AAPL.csv /kaggle/input/nab/realTweets/realTweets/Twitter_volume_IBM.csv /kaggle/input/nab/realTweets/realTweets/Twitter_volume_FB.csv /kaggle/input/nab/realTweets/realTweets/Twitter_volume_GOOG.csv /kaggle/input/nab/realAdExchange/realAdExchange/exchange-2_cpm_results.csv /kaggle/input/nab/realAdExchange/realAdExchange/exchange-4_cpc_results.csv /kaggle/input/nab/realAdExchange/realAdExchange/exchange-4_cpm_results.csv /kaggle/input/nab/realAdExchange/realAdExchange/exchange-3_cpc_results.csv /kaggle/input/nab/realAdExchange/realAdExchange/exchange-2_cpc_results.csv /kaggle/input/nab/realAdExchange/realAdExchange/exchange-3_cpm_results.csv
!pip install sktime
!pip install pmdarimaCollecting sktime
Downloading sktime-0.13.4-py3-none-any.whl (7.0 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.0/7.0 MB 12.8 MB/s eta 0:00:00
Requirement already satisfied: statsmodels>=0.12.1 in /opt/conda/lib/python3.7/site-packages (from sktime) (0.13.2)
Requirement already satisfied: scikit-learn<1.2.0,>=0.24.0 in /opt/conda/lib/python3.7/site-packages (from sktime) (1.0.2)
Requirement already satisfied: numba>=0.53 in /opt/conda/lib/python3.7/site-packages (from sktime) (0.55.2)
Collecting deprecated>=1.2.13
Downloading Deprecated-1.2.13-py2.py3-none-any.whl (9.6 kB)
Requirement already satisfied: pandas<1.6.0,>=1.1.0 in /opt/conda/lib/python3.7/site-packages (from sktime) (1.3.5)
Requirement already satisfied: scipy<1.9.0 in /opt/conda/lib/python3.7/site-packages (from sktime) (1.7.3)
Requirement already satisfied: numpy<1.23,>=1.21.0 in /opt/conda/lib/python3.7/site-packages (from sktime) (1.21.6)
Requirement already satisfied: wrapt<2,>=1.10 in /opt/conda/lib/python3.7/site-packages (from deprecated>=1.2.13->sktime) (1.12.1)
Requirement already satisfied: setuptools in /opt/conda/lib/python3.7/site-packages (from numba>=0.53->sktime) (59.8.0)
Requirement already satisfied: llvmlite<0.39,>=0.38.0rc1 in /opt/conda/lib/python3.7/site-packages (from numba>=0.53->sktime) (0.38.1)
Requirement already satisfied: python-dateutil>=2.7.3 in /opt/conda/lib/python3.7/site-packages (from pandas<1.6.0,>=1.1.0->sktime) (2.8.2)
Requirement already satisfied: pytz>=2017.3 in /opt/conda/lib/python3.7/site-packages (from pandas<1.6.0,>=1.1.0->sktime) (2022.1)
Requirement already satisfied: joblib>=0.11 in /opt/conda/lib/python3.7/site-packages (from scikit-learn<1.2.0,>=0.24.0->sktime) (1.0.1)
Requirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/lib/python3.7/site-packages (from scikit-learn<1.2.0,>=0.24.0->sktime) (3.1.0)
Requirement already satisfied: patsy>=0.5.2 in /opt/conda/lib/python3.7/site-packages (from statsmodels>=0.12.1->sktime) (0.5.2)
Requirement already satisfied: packaging>=21.3 in /opt/conda/lib/python3.7/site-packages (from statsmodels>=0.12.1->sktime) (21.3)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /opt/conda/lib/python3.7/site-packages (from packaging>=21.3->statsmodels>=0.12.1->sktime) (3.0.9)
Requirement already satisfied: six in /opt/conda/lib/python3.7/site-packages (from patsy>=0.5.2->statsmodels>=0.12.1->sktime) (1.15.0)
Installing collected packages: deprecated, sktime
Successfully installed deprecated-1.2.13 sktime-0.13.4
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
Collecting pmdarima
Downloading pmdarima-2.0.1-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.manylinux_2_28_x86_64.whl (1.8 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.8/1.8 MB 5.5 MB/s eta 0:00:00
Requirement already satisfied: statsmodels>=0.13.2 in /opt/conda/lib/python3.7/site-packages (from pmdarima) (0.13.2)
Requirement already satisfied: Cython!=0.29.18,!=0.29.31,>=0.29 in /opt/conda/lib/python3.7/site-packages (from pmdarima) (0.29.32)
Requirement already satisfied: scikit-learn>=0.22 in /opt/conda/lib/python3.7/site-packages (from pmdarima) (1.0.2)
Requirement already satisfied: joblib>=0.11 in /opt/conda/lib/python3.7/site-packages (from pmdarima) (1.0.1)
Requirement already satisfied: scipy>=1.3.2 in /opt/conda/lib/python3.7/site-packages (from pmdarima) (1.7.3)
Requirement already satisfied: setuptools!=50.0.0,>=38.6.0 in /opt/conda/lib/python3.7/site-packages (from pmdarima) (59.8.0)
Requirement already satisfied: numpy>=1.21 in /opt/conda/lib/python3.7/site-packages (from pmdarima) (1.21.6)
Requirement already satisfied: urllib3 in /opt/conda/lib/python3.7/site-packages (from pmdarima) (1.26.12)
Requirement already satisfied: pandas>=0.19 in /opt/conda/lib/python3.7/site-packages (from pmdarima) (1.3.5)
Requirement already satisfied: python-dateutil>=2.7.3 in /opt/conda/lib/python3.7/site-packages (from pandas>=0.19->pmdarima) (2.8.2)
Requirement already satisfied: pytz>=2017.3 in /opt/conda/lib/python3.7/site-packages (from pandas>=0.19->pmdarima) (2022.1)
Requirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/lib/python3.7/site-packages (from scikit-learn>=0.22->pmdarima) (3.1.0)
Requirement already satisfied: patsy>=0.5.2 in /opt/conda/lib/python3.7/site-packages (from statsmodels>=0.13.2->pmdarima) (0.5.2)
Requirement already satisfied: packaging>=21.3 in /opt/conda/lib/python3.7/site-packages (from statsmodels>=0.13.2->pmdarima) (21.3)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /opt/conda/lib/python3.7/site-packages (from packaging>=21.3->statsmodels>=0.13.2->pmdarima) (3.0.9)
Requirement already satisfied: six in /opt/conda/lib/python3.7/site-packages (from patsy>=0.5.2->statsmodels>=0.13.2->pmdarima) (1.15.0)
Installing collected packages: pmdarima
Successfully installed pmdarima-2.0.1
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
import numpy as np
import pandas as pd
import seaborn as sns
import sktime as sktime
import matplotlib.pyplot as pltThe basic workflow when using SKTime is as follows:
- Specify data
- Specify task
- Specify model
- Fit
- Predict
SKTime also provides some sample datasets and other utilities under the sktime namespace:
from sktime.datasets import load_shampoo_sales
from sktime.utils.plotting import plot_seriesdf_shampoo = load_shampoo_sales()
plot_series(df_shampoo)(<Figure size 1152x288 with 1 Axes>, <AxesSubplot:ylabel='Number of shampoo sales'>)

Forecasting
Forecasting works by taking the input data and trying to calculate what the data will be after X time period
This requires us to define a ForecastingHorizon which is the period of time over which we want to predict. sktime also has helpers for these
from sktime.forecasting.base import ForecastingHorizon# timeframe to predict from
prediction_start = df_shampoo[-6:].index[0]
prediction_range = pd.period_range(prediction_start.start_time, freq=prediction_start.freqstr, periods=6)
prediction_rangePeriodIndex(['1993-07', '1993-08', '1993-09', '1993-10', '1993-11', '1993-12'], dtype='period[M]')
fh_shampoo = ForecastingHorizon(
prediction_range,
is_relative=False
)train_cutoff = df_shampoo[-6:].index[0]
train_cutoffPeriod('1993-07', 'M')Train/Test Split
Splitting train and test data can be done by specifying the forecasting horizon, this will return a test set and train set where the test set is in the forecasting horizon
from sktime.forecasting.model_selection import temporal_train_test_splity_train, y_test = temporal_train_test_split(df_shampoo, fh=fh_shampoo)plot_series(y_train, y_test, labels=["y_train", "y_test"])(<Figure size 1152x288 with 1 Axes>, <AxesSubplot:ylabel='Number of shampoo sales'>)

Forecasting Based on Test/Train Data
This is done similar to sklearn models:
- Instantiate model
- Fit model
- Predict
- Evaluate
To enable this methodology, sktime provides different forecasting models that can be used. Below is an example using a NaiveForecaster:
from sktime.forecasting.naive import NaiveForecaster
NaiveForecaster?forecaster = NaiveForecaster(strategy="drift", window_length=10)
forecaster.fit(y_train)NaiveForecaster(strategy='drift', window_length=10)
Once fitted, generate predictions using the ForecastingHorizon that was defined for the prediction period
y_pred = forecaster.predict(fh_shampoo)plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])(<Figure size 1152x288 with 1 Axes>, <AxesSubplot:ylabel='Number of shampoo sales'>)

Model Evaluation
from sktime.performance_metrics.forecasting import mean_absolute_percentage_errormean_absolute_percentage_error(y_test, y_pred)0.16469764622516225
ARIMA Example
We can also use an ARIMA model for example as follows:
from sktime.forecasting.arima import AutoARIMA# sp=12 for monthly data seasonality
forecaster = AutoARIMA(sp=12, suppress_warnings=True)
forecaster.fit(y_train)AutoARIMA(sp=12, suppress_warnings=True)
y_pred = forecaster.predict(fh=fh_shampoo)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])(<Figure size 1152x288 with 1 Axes>, <AxesSubplot:ylabel='Number of shampoo sales'>)

Using SKLearn Regressors
sktime also supports using sklearn regressors and supports transforming them into time-series compatible regressors by way of the make_reduction function:
from sklearn.neighbors import KNeighborsRegressor
from sktime.forecasting.compose import make_reduction
from sktime.datasets import load_airline
airline_df = load_airline()y_train, y_test = temporal_train_test_split(airline_df, test_size=12)
plot_series(y_train, y_test, labels=["y_train", "y_test"])(<Figure size 1152x288 with 1 Axes>, <AxesSubplot:ylabel='Number of airline passengers'>)

fh = ForecastingHorizon(y_test.index, is_relative=False)transform a regressor into a forecaster
regressor = KNeighborsRegressor(n_neighbors=3)
forecaster = make_reduction(regressor, strategy="recursive", window_length=12)forecaster.fit(y_train, fh=fh)RecursiveTabularRegressionForecaster(estimator=KNeighborsRegressor(n_neighbors=3),
window_length=12)y_pred = forecaster.predict(fh=fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])(<Figure size 1152x288 with 1 Axes>, <AxesSubplot:ylabel='Number of airline passengers'>)
